
Don't miss news and trends when you are on vacation
When you are on vacation or don't have time to read all your favorite news sources on a given day, you might miss current news and trends which are happening and updated every day.
There are days in which I just don't want to get online for reading news and browsing. At the same time I don't want to miss the trends and highlights which are relevant on a given day. With few lines of perl code, wget, cronjob, problem is solved. Hope this helps others too.
Some of this is very straight fwd. However, I am including detailed description so that everyone gets it without questions.
Installation steps:
- download this file > vbr.tar.gz
- tar xvfz vbr.tar.gz
- cd vbr; ls You will see four files. vbr.pl - worker perl script which does the wget fetching and saving the html files to relevant directories vbr.cron - crontab input file to schedule list - list of websites that you want to archive vbr.cmd - command file to tie perl script and input file
- pwd This is your present working directory. e.g.: /home/srini/Projects/vbr
- Change paths in "vbr.cmd", "vbr.cron" - you can use your favorite text editor for this Change /home/srini/Projects/vbr/ - to your pwd from step 4.
- Add or modify sites that you want to archive in "list" First column is the web location. Second column is the directory name that you want to save the archive files to.
- View and modify "vbr.cron" file to schedule events. Edit mins/hours when you want to get snap shot of web sites
- crontab -l If this returns nothing, jump to step 9 If you have other events already scheduled, do crontab -e and append the contents of "vbr.cron" to the list and you are done.
- crontab -i vbr.cron This will register jobs with crontab
All your html pages will be saved under <your pwd from step 4>/pages/<sitename that you assigned>
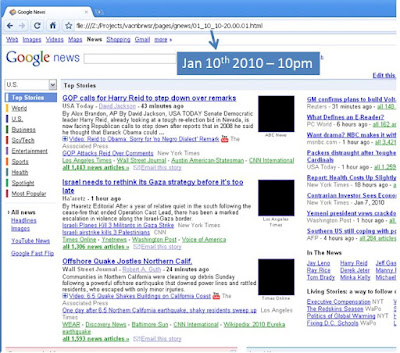
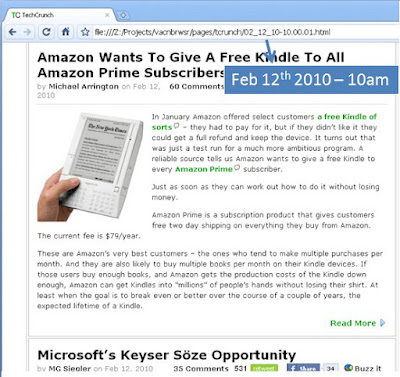
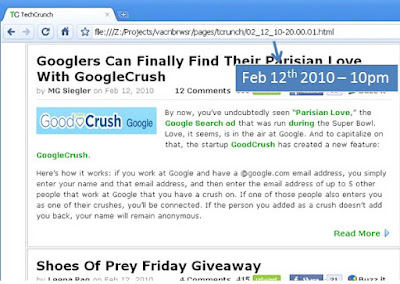
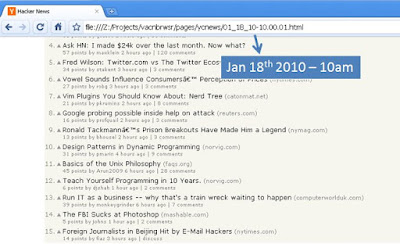
Sample pages:
No comments:
Post a Comment